
甚麼樣的raw data是可以當作我們的特徵呢???今天我們想要預測一樣東西可能房價、股票、某些特定的行為,集使我們擁有以上我們想進行問題的特徵,那又有問題出現了,甚麼樣的特徵才是所謂好的特徵呢??以下有五個要點要去注意。
我們利用舉例的方式來幫助大家理解
假設我們今天希望知道上面這間漂亮的房子要賣多少錢那甚麼是對於「價錢』是有正相關的呢?
這些對於房價都是有關連性的,就連人類買房子也會觀察這些要素,那機器有甚麼不把這些特徵納入的原因呢?
但像是有沒有草地、要不要收管理費、裡面的地板材質這些特徵對於目標好像就不是有那麼大的關係。
這問題主要是在說,若是今天我預測的數據其實是一直做改變的那要怎麼辦呢??
以上面的例子來說誰可以保證房價有沒有可能一夕之間崩盤或是暴漲,沒有人可以確定啊
機器學習的永遠是過去的事物,他只是依照過去的經驗來推算未來
這邊舉了一個例子,關於折價券的問題,利用上個月折價券的相關特徵,來推算使用未來人數,這邊有幾個特徵是可以參考的依據
這些都是可以參考的過去依據,做ML最怕的就是發現訓練好的模型並不能被使用,在做特徵萃取的時候就應該依照特徵的特性來做選取會是比較好的方式。
這邊沿用上面折價券的問題
我們需要去量化我們折價券的使用,那要怎麼量化呢??
我們可以依照一些面向去看
當然到這邊一定會有人提出質疑,舉字體這個例子好了,字體又不是數字要怎麼量化?
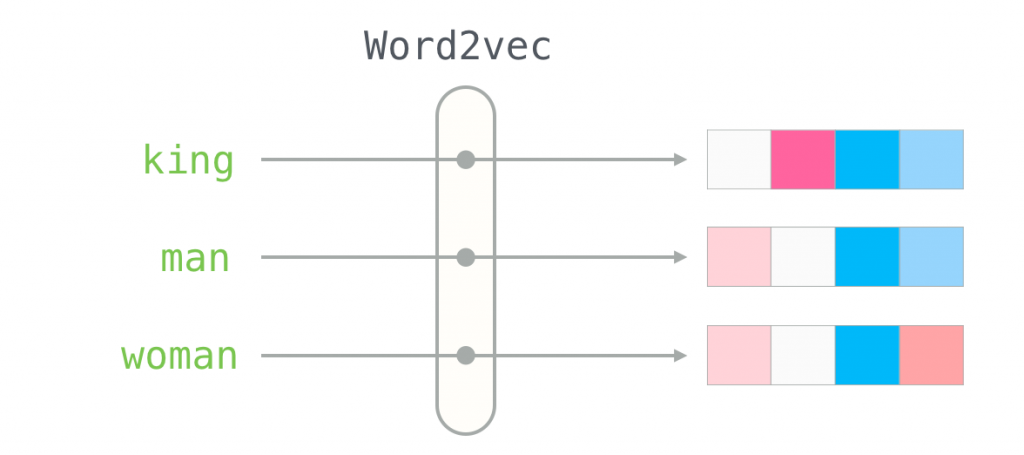
最常見的方法就是把他做Word2vec,那甚麼又是Word2vec?
Word2vec簡單來說就是把文字變成向量,把文字轉換置相對應的向量當中,而向量就只是一連串的數字組合而成,那我是不是可以量化字體這個東西了
這部分其實可以不用多做解釋,舉個簡單的例子
今天希望了解信用卡有沒有被盜刷,最簡單的一些特徵
這邊舉的特徵全部都是需要有足夠的example才有辦法做計算,有哪台機器能夠有上述特徵的其中一筆資料就可以預測出結果??
再舉一個更簡單的例子,希望得到某些青少年使用手機的頻率,然後我的資料集分布卻是0~50歲
這樣也就算了,那如果青少年分布的比例只有訓練資料的一半,那這個問題除了沒有足夠的特徵,也沒有實際的資料能夠表示我想解決的問題,基本上這目標一開始就定義錯了。
這問題有點抽象,甚麼叫做人類可以規範的問題
我這邊利用投影片上冰淇淋銷售的問題來做解釋
這邊有一個銷售格式的資料
我們可以很明顯看到
這些都是很容易做解釋的數字也是能夠拿來使用的特徵,那transactionId呢?這好像就不是那麼重要
那如果今天我們希望找到賣的最好的職員那employeeId是不是變的很重要了,職員編號723658感覺起來可以做訓練
但我的編號從0~723658中間只有五位員工現在還在這家公司工作,有必要把中間這麼多的數字來做去除嗎??
這便介紹一個方法叫做one-hot encoded,如下圖所示,我能夠利用五組數字的排列組合代表現在訓練的是哪一位
對於機器來說這更為直觀,因為他本來就是在處理0、1的事情不是嘛?
當然tensorflow一定也支援這些方式
等到明天實際做實驗的時候就會遇到了,我們到時候再仔細講述相關步驟與原理。
※圖片參考至 Feature Engineering resource





 iThome鐵人賽
iThome鐵人賽